文章目录
- 一、问题分析
- 二、控制kafka消费速度属性
- 三、案例描述
一、问题分析
Java增加线程通常是为了提高程序的并发处理能力,但如果Kafka仍然消费很慢,可能的原因有:
- 网络延迟较大:如果网络延迟较大,即使开启了多线程,也可能无法发挥作用。
- 线程数量不合理:如果线程数量过少,可能无法充分利用多核 CPU 的优势;如果线程数量过多,则会增加 CPU 调度和内存管理的开销,导致性能下降。
- 消息处理速度较慢:如果消息处理速度较慢,即使开启了多线程,仍然可能无法提高处理速度。
- Kafka 集群配置不合理:如果 Kafka 集群的配置不合理,例如分区数量过少,则可能导致消费速度较慢。
- 消费者和生产者之间的吞吐量不匹配:如果消费者的吞吐量远低于生产者,则可能导致消费速度较慢。
- 消息堆积:如果消费者无法及时处理消息,则可能导致消息堆积,从而降低消费速度。
- 其他原因:还可能是由于其他原因导致消费速度较慢,例如硬件性能较差、操作系统负载较高等。
解决方法:
检查Kafka服务器性能,确保硬件资源充足,Kafka配置优化。
如果是单线程处理能力不足,可以考虑使用多线程或增加处理能力的服务器。
检查消费者端配置,确保消费者数量足够,消费者组管理正常。
监控系统资源,如果资源不足,应进行扩容或优化。
具体解决方案需要结合实际情况分析日志、监控数据等,并根据实际情况调整配置或代码。
kafka_23">二、控制kafka消费速度属性
控制Kafka消费速度可以通过调整Kafka消费者客户端的配置参数来实现。以下是一些常用的参数及其说明:
-
max.poll.records: 单次调用poll()方法能够处理的最大记录数。
-
max.poll.interval.ms: 消费者处理一批消息的最大时间,超过这个时间则会被认为是"stalled"并被群组将其踢出。
概念:max.poll.interval.ms是Kafka消费者端的一个配置参数,用于设置消费者在轮询过程中处理消息的最大时间间隔。如果消费者在该时间间隔内没有完成消息处理,则被认为失去了与消费者组的连接,将被视为故障,分区将被重新分配给其他消费者。
最佳实践:合理设置max.poll.interval.ms对于保证消费者组的稳定运行和消息处理的及时性非常重要。以下是一些最佳实践建议:
根据实际业务需求和消息处理的复杂性,设置合理的max.poll.interval.ms值,以确保消费者有足够的时间来处理消息。
考虑到网络延迟和消息处理的时间,建议将max.poll.interval.ms设置为较大的值,以避免过早地将消费者标记为故障。
同时,也要注意将max.poll.interval.ms设置为一个合理的值,以避免消费者长时间无响应而导致消息处理的延迟。 -
fetch.min.bytes: 服务器响应请求的最小数据量,默认为1(即最小响应大小为1字节)。
-
fetch.max.bytes: 服务器响应请求的最大数据量,默认为52428800(大约50MB)。
以下是一个使用kafka-python库的示例,展示如何设置这些参数:
java">from kafka import KafkaConsumer
# 设置消费者配置
consumer_config = {
'bootstrap_servers': 'localhost:9092',
'group_id': 'my-group',
'auto_offset_reset': 'earliest',
'max_poll_records': 500, # 单次poll()调用最多消费500条消息
'max_poll_interval_ms': 300000, # 最大轮询间隔设置为5分钟
'session_timeout_ms': 6000, # 心跳超时设置为6秒
'fetch_min_bytes': 1, # 最小响应大小
'fetch_max_bytes': 5242880 # 最大响应大小设置为5MB
}
# 创建消费者实例
consumer = KafkaConsumer(
'my-topic',
**consumer_config
)
for message in consumer:
# 处理消息
print(message.value)
在实际应用中,你可能需要根据实际情况调整这些参数以达到最佳的消费速度。例如,如果你希望消费者能够更快地跟上数据生产的速度,你可能需要降低max.poll.interval.ms的值;相反,如果你希望控制消费者的吞吐量以避免影响下游系统,你可能需要增加max.poll.records的值。
三、案例描述
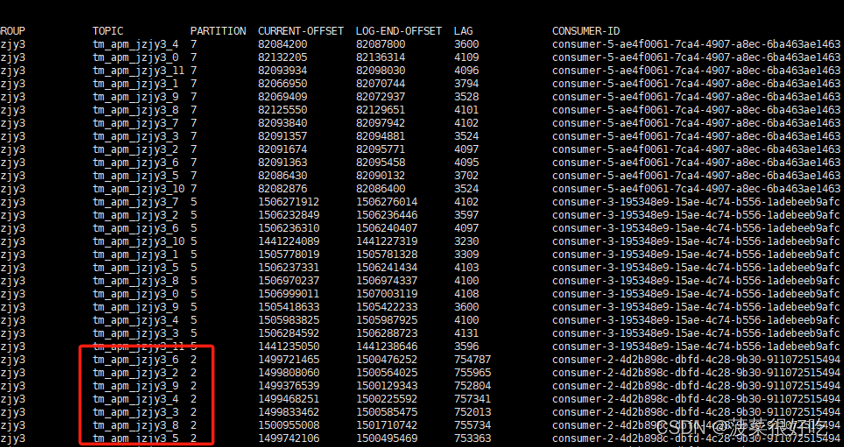
1.增加并行度,每次拉取记录数,仍然堆积,赶不上生产速度
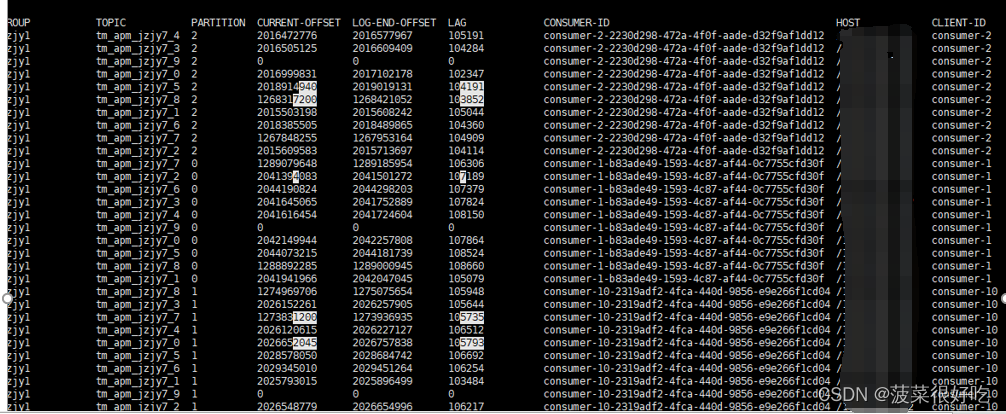
后台运行正常:
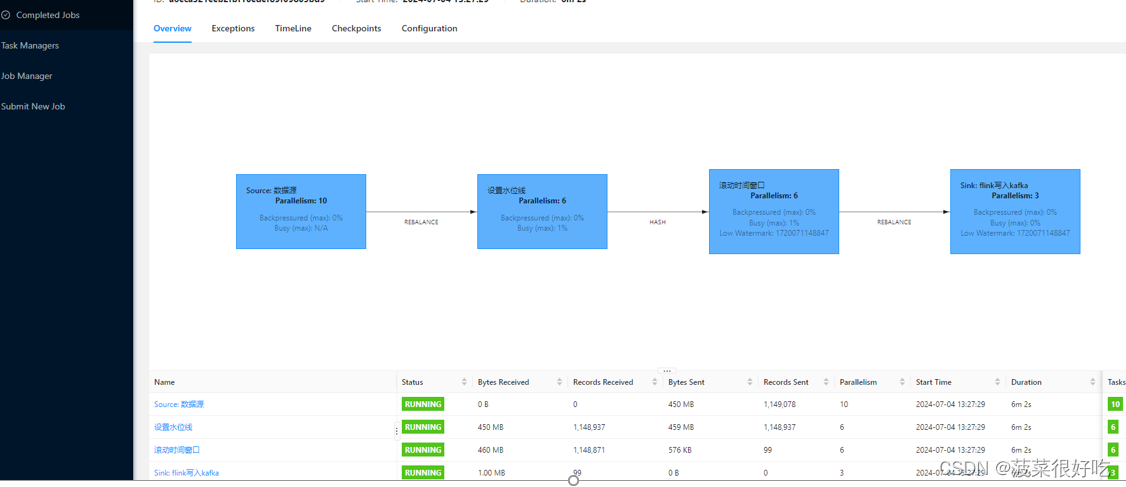
重启从最新消费,仍然有部分分区出现堆积
轮询间隔:
java">ConsumerRecords<String, String> records = consumer.poll(1000);
场景描述:
1.在堆积大量数据情况下,服务极限运行,此时无论增加多少并行度都不起作用。打印拿到数据后业务处理时间不足1秒,每次拉取500条,消费列表依然堆积增大。
2.偶尔出现心跳超时,导致kafka重新reblance,提示减少每次拉取数量,增大轮询间隔
解决1:
1.consumer.poll方法中设置的超时时间取决于你的应用程序的需求。如果你希望消费者尽可能频繁地轮询Kafka以获取消息,可以设置一个较小的超时时间。如果你希望消费者在没有消息可消费时进入休眠状态,可以设置一个较大的超时时间。
超时时间设置的大小需要考虑以下因素:
消息处理的及时性:如果你希望消息能够得到及时处理,则需要设置较小的超时时间。
网络延迟:如果你的网络延迟较高,则可能需要设置更长的超时时间。
资源使用:过长的超时时间会导致CPU和内存资源的无效占用。
一个合适的超时时间设置可能是100到500毫秒。这个时间足够短,可以保证及时检查新消息,而长于网络延迟,从而避免无意的轮询开销。
java">// 创建消费者实例
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 轮询消息,超时时间设置为100ms
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
// 处理消息
}
}
在这个例子中,poll方法被调用时设置了一个100毫秒的超时时间。这样可以在有消息可消费时及时处理它们,同时在没有消息时减少CPU的使用。